Tapestry Project Overview
This is post is an overview of the current state of my Tapestry Project
Contents
- Abstract
- Introduction
- Motivation
- Target Developer Experience
- Target Compiler Researcher Experience
- Loom Modular IR
- Validation Reporting Tooling
- Metakernels
- Graph Rewrite Rules
- Optimization
- Target Environments
- Needs
Abstract
The goal of the Tapestry Project is to provide a complete and developer-friendly aggressive toolchain for generating, visualizing, transforming, compiling, and optimizing AI and scientific computing applications which are optimized for a variety of target architectures.
The existing GPU-accelerated tensor environments (such as PyTorch) are largely focused on providing a near drop-in equivalents for the Numpy Api, and their focus on user-friendliness and compatibility with existing codebases has impeded R&D efforts towards aggressive optimization of tensor applications.
Existing tensor applications often have run costs in the 10k GPU-year range; and even small improvements in the efficiency of the above libraries translates into millions of dollars of savings in power and compute resources.
A ground-up re-imagination of the development tensor algebra is possible on the back of the polyhedral model, and this opens the possibility of a new generation of tensor algebra which is optimized for aggressive re-write operations; replacing small efficiency gains with large double-digit percentage gains.
The target developer experience should resemble modern SQL or Apache Spark / Apache Beam development, where expressions can be built up using symbolic operations, and passed to either compilers or execution engines which can produce optimized code for a variety of target architectures.
The target compiler researcher experience should permit developers and researches focused in tensor algebras, polyhedral models, compiler optimizations, and system engineering pragmatics (such as RDMA transfers, or GPU kernel programming) to work independently of each other, and to produce and share their work in a way which is compatible with the work of others.
The Tapestry Project is built upon a modular and extensible IR (intermediate representation) called loom, which permits strict targeted sub-dialects for each transform layer, with appropriate graph semantics constraints, visualizers, and debuggers. This further contributes to layer-isolation for development and research.
By developing and exploiting the layers, symbolic execution graphs can be transformed into concrete polyhedral type operation graphs, and then sharded and optimized for different families of target execution environments.
Directly competing with large existing compiler/language toolchains is an expensive task; and the primary goal of Tapestry is to develop tools at each stage which reduce the future costs of R&D on Tapestry, in support of being able to build the strongest possible optimizer for the restricted polyhedral type tensor block expression algebra which Tapestry represents.
We are recruiting project development resources, research and implementation contributors, and grant funding frameworks to further develop the project.
Introduction
The goal of the Tapestry Project is to develop a complete and developer-friendly toolchain for generating, visualizing, transforming, compiling, and optimizing polyhedral type tensor block algebra expressions into optimized code for a variety of target architectures.
That’s a mouthful, so let’s break it down.
A tensor algebra expression is a mathematical expression that involves tensors, which are multidimensional arrays of numbers. For example, a matrix is a 2-dimensional tensor, and a vector is a 1-dimensional tensor. Tensor algebra is a generalization of matrix algebra, and is used in many scientific and engineering applications, such as artificial intelligence, quantum mechanics, fluid dynamics, and computer graphics.
An expression in a tensor algebra derives its value from a series of functional operations performed on one or more tensors; and producing one or more tensors, for example, consider a basic matrix multiplication:
1 | A := <Tensor of size (m, n)> |
In compiler optimization, it is often useful to produce re-write rules, which state that one general form of an expression can be transformed into another form that is at least equivalent, and preferably more efficient to calculate. For example, the above expression can be re-written as a composition of two operations (which in this case will probably not produce any benefit):
1 | A := <Tensor of size (m, n)> |
Lacking further visibility into the internals of the operations, optimizers are limited to re-writing expressions based on these re-write rules; and on altering where and when operations are scheduled to run.
If we observe that many tensor operations are block operations, in that they operate independently on subsets of their inputs in such a way that it is possible to split them into smaller operations and re-combine the results, we begin to see that there is a potential for optimization which looks inside the operations in its restructuring.
The polyhedral model or polytope model provides a framework for describing some block operations in a way which permits direct reasoning about sub-sharding and recombination of the operations; without knowledge of the internals of the operation itself.
The term polyhedral type signature has come to be used to describe the spatial type of an operation as it is described in the polyhedral model. This is a generalization of the term block operation to include the spatial type of the operation.
By extending a tensor block algebra with polyhedral type signatures, we can describe expressions of block operations in a way that permits direct reasoning about sub-sharding and recombination of the component operations, in addition to the above graph re-writing and scheduling.
1 | A := <Tensor of size (m, n)> |
This is discussed in much greater detail in the Polyhedral Types and Index Projection document.
A polyhedral type tensor block algebra optimizer toolchain is directly analogous to the SQL model; where the SQL language permits the user to describe the what of a query in terms of relational algebra, and the SQL engine, by applying aggressive query optimization arrives at a query plan which is equivalent to the original query, but is more efficient to execute.
Motivation
The space of GPU-accelerated tensor environments is already dominated by a few well-known ecosystems; most notably PyTorch, TensorFlow, and Jax.
The semantics of these environments take strong motivation from the NumPy API, which is a popular library for numerical computing in Python; and is itself a partial clone of R, a popular language for statistical computing. These statistical libraries have deep roots in the statistical and artificial intelligence communities, and have been optimized for the ease of use of researchers, analysts, and developers working in statistics, signal processing, and artificial intelligence.
As sharding and re-write safe semantics are complex mathematical properties, they are not present by default in expression algebras; the algebras must be carefully designed to support them, and must strictly exclude operations which are not compatible with these properties.
The semantics of NumPy’s operations were not designed with sharding and aggressive re-write operations in mind; and while a large portion of the api surface is compatible with the necessary restrictions, a significant portion is not. Complicating the matter, the libraries are generally embedded in interpreted languages, and frequently intermixed with arbitrary code in those languages.
In order to successfully extract a polyhedral type tensor block algebra expression from a PyTorch program; it is necessary to retro-fit signatures onto PyTorch, to write python code walking analysis, and to force that code to lie inside a complex semantic boundary which is difficult to explain to users. Despite this, due to the high machine costs of large tensor operations, a number of projects attempt to do just this; at larger and larger costs for smaller and smaller gains.
A single training run of a large AI model can cost more than $100M; and the execution lifetime of a trained model can easily consume 10k GPU-years.
A ground-up re-imagination of the development tensor algebra is possible on the back of the polyhedral model, and this opens the possibility of a new generation of tensor algebra which is optimized for aggressive re-write operations; replacing small efficiency gains with large double-digit percentage gains.
The development cost is akin to bootstrapping any new optimizing compiler; and the primary goal of the Tapestry project is to develop tools at each stage which reduce the future costs of R&D on Tapestry, in support of being able to build the strongest possible optimizer for the restricted polyhedral type tensor block expression algebra which Tapestry represents.
The expectation is not a drop-in replacement for PyTorch, Jax, or NumPy; not an environment where Tensor operations freely intermix with arbitrary code; but something more akin to SQL or Apache Spark/Beam, where expressions are built up using symbolic operations, and passed to either compilers or execution engines which can produce optimized code for a variety of target architectures.
If we take the machine budgets of existing AI companies at face value, where some companies have $1B/year machine budgets; finding a 10% improvement in the efficiency of the optimizer would be worth $100M/year to that company.
PyTorch, TensorFlow, and Jax are all pursuing the top-end of this problem; seeking ways to improve the efficiency of code written using their runtime / semantics models, without changing the semantics of the code.
Tapestry is pursuing the bottom-end of this problem; seeking a better foundation for the development of tensor algebra expressions, with a target on never needing to develop program-understanding code scanners, or back port missing semantics to the tensor algebra.
Target Developer Experience
The goal of the Tapestry project is to provide a complete and developer-friendly toolchain for generating, visualizing, transforming, compiling, and optimizing polyhedral type tensor block algebra expressions into optimized code for a variety of target architectures.
The developer experience should resemble modern SQL development; or symbolic execution data flow languages such as Apache Beam or Apache Spark.
Expressions can be built up using symbolic operations (which produce a description of the work, rather than immediately doing the work), and passed to either compilers or execution engines which can produce optimized code for a variety of target architectures.
For example, the following symbolic expression:
1 | Tensor input = ...; |
Could be expanded and manipulated in various stages of transformation to expand and optimize the code in a variety of ways, and then passed to a compiler or execution engine to produce optimized code for a variety of target architectures:
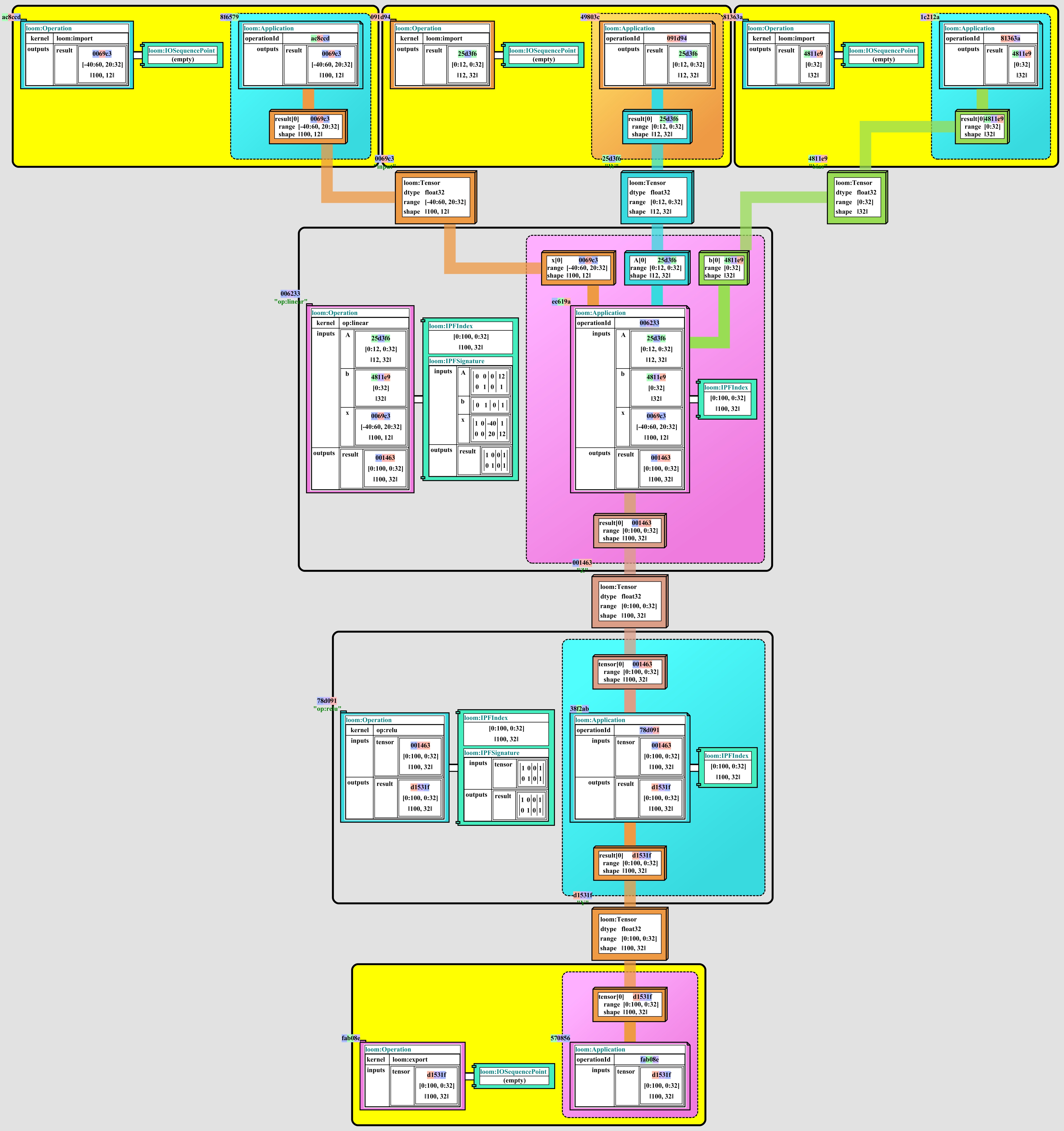
|
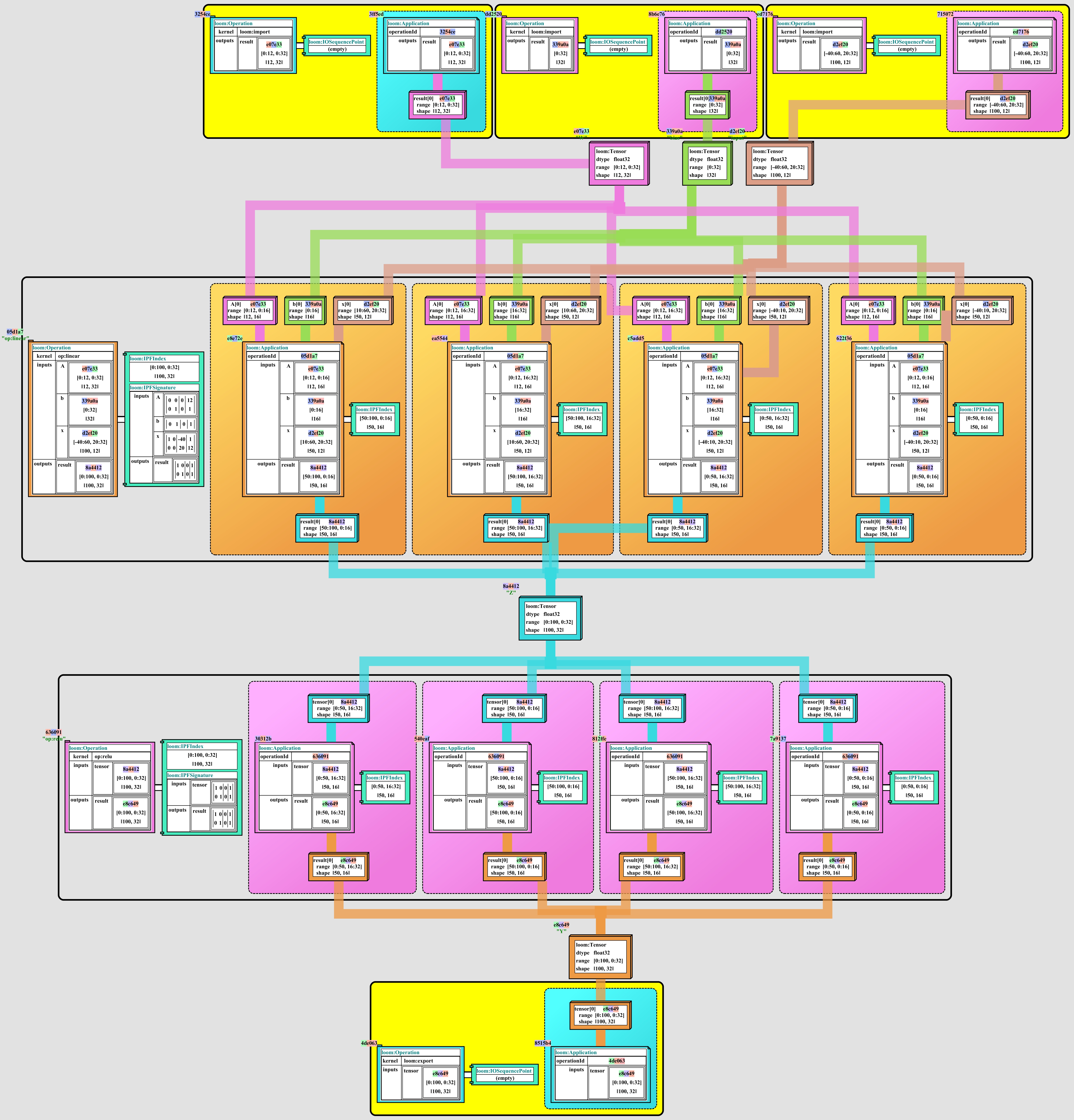
|
Additionally, the toolchain should provide a rich set of debugging and visualization tools for exploring the intermediate representations of the expressions, and for exploring the optimizations applied to the expressions.
Target Compiler Researcher Experience
- Good R&D Tools => Cheap R&D Cycles
- Cheap R&D Cycles => More R&D Cycles
- More R&D Cycles => Greater Velocity
- Therefore,
- Good R&D Tools => Greater Velocity
A critical goal of the Tapestry project is to provide as much support to internal development and research teams as possible, to reduce the future costs of R&D on Tapestry.
The development cost of new graph re-write rules, new metakernels, and new target environments and cost models should be easy to write, easy to visualize, easy to validate, and easy to debug.
To this extent, the validation reporting tooling, constraint validation system, and associated tooling for mechanically constructing and reporting complex errors, reporting them in structured data, and visualizing those errors in common formats, such as rendered as text for exception handlers, is a major part of the Tapestry project.
Loom Modular IR
IR is Destiny.
A compiler’s internal representation (commonly called the intermediate representation, as it exists between the source code which was parsed and the target code to be generated) determines most things about the complexity and capabilities of the compiler.
Information which can be retrieved or verified easily in an IR can be used for analysis and manipulation with a little code; information which is fragile or difficult to retrieve or verify requires a lot of code to work with. And code which is difficult to work with is code which is difficult to maintain, and difficult to extend.
In targeting a toolchain which spans from abstract tensor algebra expressions to optimized code for a variety of target architectures, the IR is the most important part of the toolchain; and the ability to extend and constrain the IR for different layers of that toolchain, and for different primitives appropriate to different target architectures, is the most important part of the IR.
Tapestry is designed with a modular IR which permits the easy addition of new node types, node tags, and graph constraints. By selectively including a set of types and constraints, strictly defined sub-dialects can be created which are appropriate for different layers of the toolchain, and for different primitives appropriate to different target architectures.
In this way, toolchain operations which transform from one layer to another can be written in a type-safe way which transform from one dialect to another; and targeted query, debugging, and visualization tools can be written which are appropriate for the layer of the toolchain being targeted.
As the core representation, serialization, and scanning code are shared by all dialects, much of the verification and manipulation code can be shared as well; and the code which is not shared is written in a type-safe way which is appropriate for the layer of the toolchain being targeted.
The Tapestry IR is called loom.
A LoomGraph is a collection of nodes, paired with a LoomEnvironment defining constraints on what constitutes legal values and relationships for those nodes.
A raw LoomGraph is a JSON document collection of nodes:
1 | { |
Each LoomNode has:
id- a unique UUID identifierlabel- an optional, non-unique string labeltype- a string type identifierbody- atype-dependent JSON structuretags- a tag type keyed map of{<type>: <JSON>}of tag type dependent node extensions
Each node type and tag type is expected to have a corresponding schema, defined and enforced by the LoomEnvironment; and is expected to be parsable by type-dependent node wrappers, which understand the data and can provide a type-safe api for manipulating the data.
By defining additional types and constraints, we can compositionally construct language dialects with strict semantics, reusing types and constraints across several dialects.
Example
Assuming two very simple types, a tensor and a simple operation with no sharding information, we could define types and graphs such that a desaturation operation is performed on a tensor of images:
1 | { |
NOTE: The modern XML standards family provides a very strong environment for defining and validating complex data structures. The XML family is also very well-supported in many languages and platforms.
However, the standards which provide the fully fleshed out versions of schemas and query language, the 2.0/3.0 family of XSD, XPath, XQuery, and XSLT, have only one conformant implementation family, which charges very high per-seat licensing fees for the use of the software.
As such, it is not a viable target for an open-source project.
Loom Dialects
The goal of loom dialects are to define strictly limited expression IRs for a targeted layers of the toolchain.
In doing so, we can define:
- An Abstract Expression Dialect for describing applications of tensor algebra expressions, abstracted from the intermediate result shapes.
- An Operation Expression Dialect for describing concrete polyhedral type tensor algebra block expressions, decorated with polyhedral signatures and intermediate result shapes.
- An Application Expression Dialect for describing concrete block sharding of sub-operation applications, and their index locations in the polyhedral index space of their parent operation.
- Families of Target Environment Dialects, expanding the Application Expression Dialect with additional primitives and constraints to represent execution and memory placement and scheduling information for a variety of target environments.
Validation Reporting Tooling
As the a high level goal is to drive the cost of R&D on Tapestry down, a core part of the Loom environment is the constraint validation system, and the associated tooling for mechanically constructing and reporting complex errors, reporting them in structured data, and visualizing those errors in common formats, such as rendered as text for exception handlers.
Consider the following constraint error, detecting reference cycles in a graph:
Click for Validation Builder
1 |
|
Click for JSON Error
1 | [ |
1 | org.tensortapestry.common.validation.LoomValidationError: Validation failed with 1 issues: |
Metakernels
The code implementing an operation is generally referred to as the kernel for that operation. Given actual data for an operation, calling the kernel in an appropriate environment will validate the structure of that data (correct parameters and inputs passed, etc), and produce a result.
To describe the behavior of a kernel we do not wish to execute, but to symbolically execute, processing not data, but symbolic descriptions of data, we need a program which will consume the symbolic representation of the inputs and parameters, validate that they are well formed versus the kernel’s expectations, and produce a symbolic representation of the expected outputs of the kernel.
In Tapestry we call this program a metakernel, at it is executed on the symbolic level, rather than the data level.
Tapestry requires that for each kernel we wish to represent in a symbolic execution graph, we have a corresponding metakernel which can be applied to symbolic representations of inputs to describe the kernel’s behavior. Additionally, this metakernel must attach a polyhedral type signature to the symbolic representation of the output, which describes the spatial type of the output in terms of the polyhedral model, to enable re-write and re-sharding operations.
As we need a metakernel for each external kernel in a target execution environment, and as we expect third party libraries and developer applications to frequently provide their own kernels, we need a way to describe metakernels in a way which is easy to write, easy to validate, and easy to share.
Were we required to write a compliant metakernel for each target kernel for each Tapestry compiler environment, the cost of R&D on Tapestry would be very high, and the cost of R&D on Tapestry for third party developers would be even higher.
A major goal of Tapestry is to reduce this cost by developing a portable template environment in which portable template metakernels can be written, validated, and shared.
Consider the following draft-proposal for a template metakernel for a matrix multiplication, which is a common operation in tensor algebra.
In this proposal, we match a shape expression language on the inputs (X and W), such that we
extract batch dimensions from the input (X), and constrain $b to match between the X and W
inputs. Then polyhedral type signatures are attached to the inputs and outputs in terms of their
matched shapes; and a common polyhedral index is used to describe the spatial extent of the
operation, and the mapping to the output.
1 | matmul: |
The work on template metakernels is ongoing, and is expected to be a major part of the Tapestry project.
Graph Rewrite Rules
Graph re-write rules are a common tool in compiler optimization, and are used to describe how one general form of an expression can be transformed into another form that is at least equivalent, and preferably more efficient to calculate. In Tapestry, graph re-write rules are used to describe how one sub-graph expression can be transformed into another equivalent form.
The intention is to heavily leverage the Metakernels template language to describe the behavior of the re-write rules, and to use the same language to describe the behavior of the metakernels which are being re-written.
This work is ongoing, and is expected to be a major part of the Tapestry project.
Optimization
Given a family of semantics preserving re-write and sharding rules, all that is needed in order to produce an initial optimizer is a way to assign value to variations in the graph.
For each given Target Environment, we can develop a target cost model which assigns a vector of labeled costs (wall-clock time, machine count, memory usage, idle resource count) to a graph expression instances.
Plural cost models are perfect fits for Pareto optimization environments; and Pareto optimization environments are embarrassingly parallel, in that we can horizontally add as many additional worker threads or machines as we like, for linear speedups in the optimization search process.
As it is common to encounter AI models which see 10k GPU-year run costs, and as it is common to encounter AI models which are run in production environments with 1000s of machines, the potential impact of even small improvements in the efficiency of the optimizer is quite large.
As the optimizer can be run in parallel, large optimization search spaces can be examined by tasking many search machines, proportional to the expected value of improvements for the given target application.
Over time, research can improve the efficiency of the optimizer, and the quality of the cost models, and the quality of the re-write and sharding rules, and the quality of the metakernels. But even initial versions of the optimizer can be expected to produce significant improvements in the efficiency of the target applications; if sufficient resources are allocated to the optimizer search process.
Target Environments
Each new target environment will likely a new loom dialect, adding primitives and constraints describing placement and scheduling of operations in the target environment.
Each new target environment will likely also require a new symbolic cost model, which assigns a vector of labeled costs (wall-clock time, machine count, memory usage, idle resource count) to a graph expression instance in the target environment’s loom dialect.
There is a possibility of sharing many common kernel (and their associated metakernels) across target environments, and the Tapestry project is expected to develop tooling to support this.
Needs
Tapestry is at a recruiting / growth stage in the project, and we are looking for the following types of support:
R&D Support
We are looking for additional technical and research contributors to help develop the project from initial research stage to a fully functional optimizer targeting PyTorch and Jax backends.
Project Support
We are looking for project management and development resources to help organize the project and recruit additional contributors.
Funding
We are looking for grant funding frameworks to further develop the project.
Historically, languages and compilers have not been successful outside of open source / free software models. Subscription compilers do exist, but as performance options when open reference compilers also exist for an environment. Developers have been historically unwilling to tie their work to a proprietary language or compiler.
Finding a funding model which is compatible with the open source / free software model for the base environment is a major goal of the project.
There are development models where the base environment is open source / free software, and support services are offered to companies which wish to prioritize their extension and development needs for the environment.
There are also models where the base environment is open source / free software, and products are developed which commercially exploit the environment under the same funding structure.